着色器
着色器(Shader)是用来实现图像渲染的,使用者为GPU,用来替代固定渲染管线的可编辑程序。使用上最为基本的着色器为顶点着色器Vertex Shader和片元着色器Fragment Shader(OpenGL)。
除此之外,像素着色器Pixel Shader(DirectX),几何着色器Geometry Shader,计算着色器Compute Shader,细分曲面着色器Tessellation or hull Shader也是目前较为常见的其他类型的着色器
由于Shader的标准并非只有一家,目前微软的DirectX以及Khronos Group协会的OpenGL、VulKan是主流的图形库,GPU厂商们对这三种图形库的支持是最好的。由于标准不一样,命名也有所不同
本文讲述的是基于OpenGL的着色器基础,采用的是GLSL(OpenGL着色语言OpenGL Shading Language).
其中Vertex Shader(顶点着色器)主要负责顶点的几何关系等的运算,Fragment shader(片元着色器)主要负责片源颜色等的计算。
着色器只是一种把输入转化为输出的程序。也是一种非常独立的程序,因为它们之间不能相互通信;它们之间唯一的沟通只有通过输入和输出。
着色器替代了传统的固定渲染管线,可以实现3D图形学计算中的相关计算,由于其可编辑性,可以实现各种各样的图像效果而不用受显卡的固定渲染管线限制
Tips: 固定渲染管线是嵌入硬件中不可外界编程的
为什么需要Shader
当计算机在绘制任何2D或3D图形时,其根本的显示形式是图元Primitives或者网格Mesh。比如游戏中一个几何模型角色或一个贴在了网格上的纹理角色,比如在做阴影效果时也会先绘制网格再计算阴影,这些都可归结为网格Mesh,而网格又可被分解为一个个的图元,即图元是网格的基本单位。而图元有三角形、直线或点。这些是计算机图形绘制的基本常识。
由于计算机自身的架构设计,计算机CPU的任务执行方式是串行。即一次一个地依序完成。可以把 CPU 想象为一条管道,然后有许许多多的任务都是通过这个管道的处理来完成,它就像一个生产流水线。
当然这条生产线所执行的任务规模并不一模一样,有些规模会更加的大,也就是说一条管道将需要要花费更多时间和精力去处理。如果想要提升处理速度,那么就需要更强的处理能力。远古时期计算机的的确确只有一条管道,但是现代计算机通常有四个核心的CPU,也就是具有四个管道,而一般会把这些管道称为线程。四个管道一起来处理成堆的事务时,显然比一条管道更加有效。
当使用了因特尔的多核超线程技术时,由于利用了特殊的硬件指令,单个物理核心可以模拟成两个核心(逻辑核心),每个物理核心都可以拥有两个管道,减少了CPU的闲置时间,提高的CPU的运行效率。这样计算出的4核心CPU可以拥有八个管道。
实质上使用超线程技术多出来的一个线程只比原来多30%左右的性能,而多一个物理核心性能理论上可以多一倍,可见多一个线程远没有多一个核芯的性能高。但是超线程技术的主要优势在于它只需要消耗很小的核心面积代价,就可以在多任务的情况下提供显著的性能提升,其比再添加一个物理核心来说要划算得多。
计算机绘制图像的过程并不复杂,一个图形通过计算机对每一个像素的操作后即可实现绘制。
但在所需要绘制的图像信息逐渐复杂化后,计算机所要绘制的图形远远不只于一个小小的几何形状。使用CPU来进行大规模图像绘制会渐渐变得艰难。
比如对于一个比较老式的屏幕(分辨率 800x600)来说,单帧就需要处理480000个像素,也就是每秒进行14400000次计算!而显然处理视频这样的多帧图像信息时,每秒运行60帧计算,就需要每秒进行864000000次计算!现代计算机通常采用GPU来进行图形计算,至于原因,要从CPU和GPU的设计场景来说起。
CPU设计场景
CPU作为中央处理器,需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂。
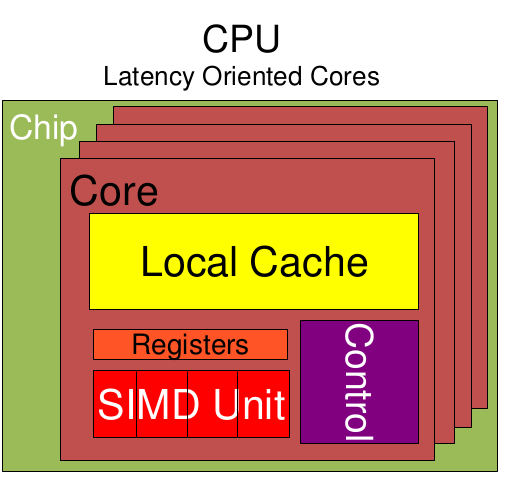
CPU的缓存单元占据了许多空间,而且还有有复杂的控制逻辑和诸多优化电路,相比之下计算能力只是CPU很小的一部分。CPU有强大的ALU(算术运算单元),这也意味着它可以在很少的时钟周期内完成算术计算。当今的CPU可以达到64bit 双精度。执行双精度浮点源算的加法和乘法只需要1~3个时钟周期。CPU的时钟周期的频率是非常高的,达到1.532~3gigahertz(千兆HZ, 10的9次方),又因为它使用了大缓存,这样CPU可以保存很多的数据放在缓存里面,当需要访问的这些数据,只要在之前访问过的,如今直接在缓存里面取即可。而CPU复杂的逻辑控制单元在执行任务含有多个分支的时候,可以使用分支预测的能力来降低延时。
简单的来说,可以把CPU理解为一位经验丰富的老教授,积分微分都会算,而且算的效率特别高。
从刚刚的864000000次计算可以看出,经验丰富的老教授虽然数学很好,但是在800000000道基本加减运算面前,老教授孤身一人计算自然是杯水车薪,心有余而力不足。图形绘制并不是特别用得上老教授的丰富经验。它仅仅需要重复的传递不同组的参数给每个像素来进行绘制即可。这样简单的重复动作用不上CPU,因此GPU便登场了。
GPU设计场景
GPU的设计场景面对的是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。采用了数量众多的计算单元和超长的流水线。这样就有了大量的管道可以用于任务进行。
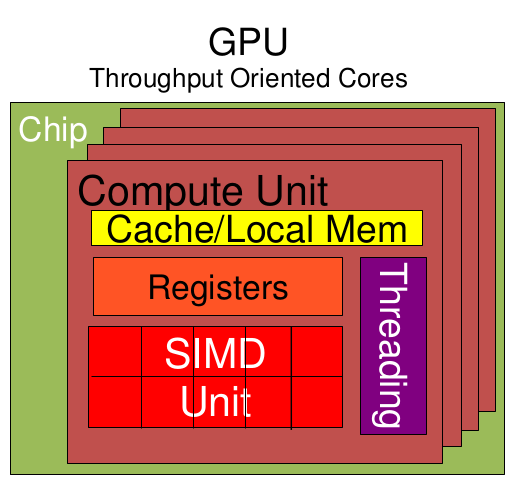
GPU物理架构的特点是有很多的ALU和很少的缓存单元. 缓存的目的不是用来保存需要访问的数据的,这点和CPU不同,而是为线程提高速度而服务的。当有很多线程都访问同一个数据时,缓存会合并这些访问,然后再去访问Dram(GPU中需要访问的数据保存在Dram而不是缓存),当获取到数据后缓存会转发这个数据给需要它的线程,由于需要访问Dram,GPU的会存在Dram延时,为了平衡内存延时的问题,GPU拥有非常多的ALU和非常多的线程.这样充分利用多的ALU的特性达到一个非常大的吞吐量。就可以尽可能多的分配线程.因此GPU的管道数量相当多。
可以看出,我们之所以选取GPU,恰好是因为设计它便是为了大规模的重复简单运算,GPU就如同30000个小学生,会进行简单的加减运算,那么图形运算这样的活恰好就可以交给拥有大量线程的GPU来干。这样在很短的时间内,GPU通过众多的管道完成了CPU难以完成的工作。
虽然扯了一大堆和Shader看似不沾边的知识点,但是这并不是跑题,因为Shader的存在意义便是为操作GPU图形处理相关的事务。如果想要画出好看的高度自定义的图像,就必须依赖于Shader对于图像的高效处理。
TIPS:
有一点非常重要,GPU 的强大的架构设计也有其限制与不足。为了能使许多管线并行运行,每一个线程必须与其他的相独立。这些线程对于其他线程在进行的运算是“盲视”的。这个限制就会使得所有数据必须以相同的方向流动。所以就不可能检查其他线程的输出结果以及修改输入的数据。或者是把一个线程的输出结果输入给另一个线程。
而且GPU会让所有并行的微处理器(管道们)一直处在忙碌的状态;每个线程不仅是“盲视”的,而且还是“无记忆”的,只要它们一有空闲就会接到新的信息。线程不可能知道它前一刻在做什么。因此某一个管道可能是这一刻还在画操作系统界面上的一个按钮的一个点,然后下一刻又渲染了你所打开的游戏中的一部分天空。
这种抽象性,和盲视、无记忆的是Shader在编程中是需要时刻牢记的要点。
一、顶点着色器 Vertex Shaders
顶点着色器告诉计算机如何处理顶点、法线等的数据,在绘制图形时,这往往是第一步。计算机图形画法和数学图形可以说基本同理,但是在顶点确定几何图形上可能有着一些不同。
就比如在绘制一个矩形贴图时,但是计算机更喜欢绘制三角形,所以这些矩形被分为了两个三角形。这样一来,每个贴图就会有六个顶点,但是其中两个是重叠的,所以顶点数量只要四个。其如图所示:

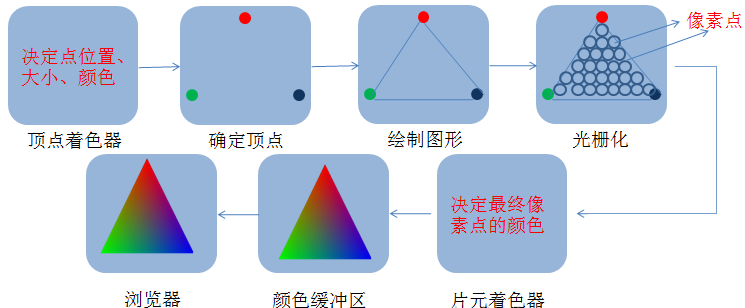
在顶点着色器负责顶点处理,计算出每个顶点的坐标,颜色,纹理坐标等等后,它将向后传输,经过光栅化之后,传给Fragment Shader
假设有一个遍历每个顶点并为每个顶点执行顶点着色器所含代码的for循环。由于顶点着色器较早执行,因此可以在将顶点坐标和颜色等信息传递给片元着色器之前对其进行更改。
光栅化 Rasterize
之所以要把光栅化单独提出来,是因为这是一个刚一听起来完全不懂它是在干嘛的那种名词。在理解光栅化之前,刚才说过,光栅化步骤前先需要得到顶点着色器给出一个矢量图形。
就比如画一个三角形时,将三角形的顶点信息给顶点着色器,形成一个矢量三角形。
矢量三角形是在一个给定的坐标系(例如齐次裁剪坐标系)中向量的集合,是数学几何的体现。它并不是屏幕所能理解的图像的像素信息。而是计算机为了理解图形“样貌”而产生的。
.
虽然已经有了一个矢量图形,但是最终在屏幕上显示的三角形是在像素点上画出来的。
那么光栅化的作用便已经很清楚了,通俗来说,光栅化就是是将一系列变换后的三角形转换为像素的过程。
除了2D图形,包括3D图形的光栅化也是类似的。
三角形转换为像素的过程,实际上就是判断像素跟三角形的关系。具体一种算法来说,可以看像素的中心点是否在三角形内(一个点是否在三角形内,就可以使用向量的叉积方式判断),如果这个点在三角形内就属于三角形,那么得到的最终效果就是这样一个三角形
.
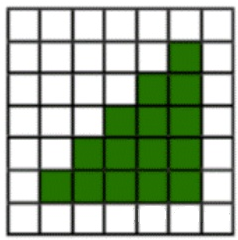
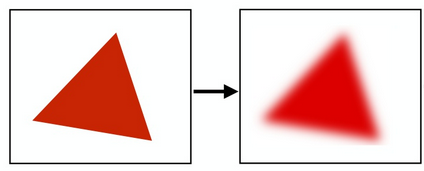
很显然这样的形状是很不理想的,因为采样获得的最终形状损失了太多细节,锯齿太过严重。通常情况下会有反走样(抗锯齿)的许多方法,
由于这是数字图像信号处理的部分,基础篇就不做过多的拓展。(◎_◎;)
了解了顶点着色器的基本工作后,我们梳理最终的描述:
在编程人员给出一组相关图形指令(GLSL指令)后,输入进来的每个顶点都会调用一次顶点着色器。顶点着色器会根据指令计算出每个顶点的坐标,颜色,纹理坐标等,然后最常见的输出便是经过光栅化后交给片元着色器进行信息的处理。
现代的Shader Model中,它还可以将数据发送给曲面细分着色器或者几何着色器进行额外处理。
此处有个误区需要注意:描述上顶点着色器决定点的大小、位置和颜色,而片元着色器是用于给像素着色的,乍一看,片元着色器的任务好像给顶点着色器完成了,但实际上,顶点着色器仅仅只能决定点的颜色而已,此时三角形还只有三个带有颜色等信息的顶点,而三顶点所定位的三角形内部的像素点填充都是光栅化以后的结果,片元着色器则负责将光栅化后的内部像素填充上颜色。
二、片元着色器Fragment Shaders
顾名思义,DirectX称其为像素着色器,而OpenGL称他为片元着色器,实质上可以看做同一种东西。在光栅器处理了图元之后,它会产生一系列需要被涂上各种颜色、纹理、光照的像素列表,然后把它传递给片元着色器。
片元着色器再负责由将传过来的颜色、纹理、光照信息等的在像素上的绘制工作。
在这个阶段会存在巨大的工作量,三角形会覆盖几百几千个甚至上百万个像素点。在现实情况中,片元着色器
是非常复杂的,会同时牵扯到光照、材质、甚至是需要计算像素的深度的信息。
前面所讲的例子中仅仅是使用了一个颜色单一的三角形,当给与的三角形顶点颜色不同时,如图所示。
GLSL代码的含义将在下一章节介绍
顶点着色器代码
var VSHADER_SOURCE =
attribute vec4 a_Position;
attribute vec4 a_Color;
varying vec4 v_Color
void main() {
gl_Position = a_Position; // 设置顶点的位置
v_Color = a_Color; // 顶点设置一个varying类型的颜色值,用于线性化处理
gl_PointSize = 10.0; // 设置顶点的大小
};
片元着色器代码
var FSHADER_SOURCE =
precision mediump float;
varying vec4 v_Color;
void main()
gl_FragColor = v_Color; // 设置像素的颜色
};
此时再把其光栅化时,由于在顶点着色器中使用了线性变化的代码,光栅化时,原本三个点所代表的的矢量三角形中所有的像素需要进行颜色信息填充,此时像素的颜色信息过渡会是一种自然线性的变化。

其具体流程如下
像素着色器的指令和顶点着色器的指令非常接近。但是值得注意的是像素着色器不能像顶点着色器那样,能够单独存在。他们在运行的时候,必须有一个顶点着色器处于被激活状态。
预告:GLSL
GLSL是一门特殊的语言,有着类似于C语言的语法, 是在图形管道(Graphic Pipeline)中直接可执行的OpenGL着色语言...详见GLSL基础与语法